Briefly describe the terms customer consent and balance interest
4. Explain how the Hadoop ecosystem can be layered as a stack. Use modules to exemplify.
5. Explain the key benefits of high-Level query languages, such as Apache Pig and Apache Hive, over developing applications directly in MapReduce?
Also explain why companies are now moving from relying on customer consent to balance of interest as legal grounds for storing and processing user data.
10. Briefly describe the terms Customer Consent and Balance of Interest. Also explain why companies are now moving from relying on customer consent to balance of interest as legal grounds for storing and processing user data.
(b) Showing the output of the sort and shuffle step.
(c) Showing the output of the reduce step. Assume the dataset has been partitioned and is stored on two compute nodes (as illustrated below), which will be used for carrying out the parallel computation. The reduce step should also be parallelized using the two compute nodes, meaning that the results will be stored in two separate files (one per node).
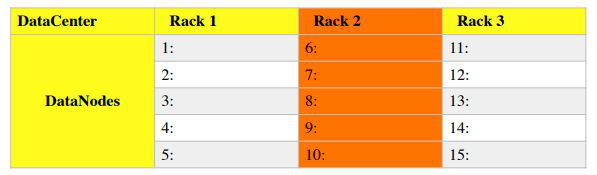
(b) Also, illustrate the block order in the Priority Queue for the under-replicated blocks below (highest to lowest).
(a) Which of the architectures introduced in the course would you use for building this system? Why?
(b) What type(s) of module(s) within the Hadoop ecosystem would you use for building this system? Why?
(c) Describe how you would go about model selection, i.e. how you would identify — among a set of alternatives — the best possible model.
(d) Describe how Spark ML helps to facilitate large-scale machine learning.
(d) There are two least-weight paths from B to F in the graph below. What are they and what is the total weight of either one of these paths?
(e) If the graph below was used to represent a social network, could the individual represented by node A be said to be a communicator? Motivate your answer.
(b) Describe and motivate which type of data store you will use for each data source. For each data source, reflect on whether you need persistent data storage or not.
(c) Describe and motivate your method(s) for analysis. Describe the goal of each model, as well as how each model will be built and applied using the available data.