
The root node split the dimension and node split the dimension
• Understand how a real-world problem can be implemented by different data structures and/or algorithms.
• Evaluate and contrast the performance of the data structures and/or algorithms with respect to different usage scenarios and input data.
Kd-trees is a binary tree data structure that enables more efficient nearest neighbour searches for spatial queries. It builds an index to quickly search for nearest neighbours. Based on the set of points to index, Kd-trees recursively partition a multi-dimensional space, and generally ensures a balanced binary tree (making search relatively fast). In this assignment we focus on 2D spaces (something we are familar with and can be visualise). In the 2D space, we have x (horizonal) and y (vertical) dimensions.
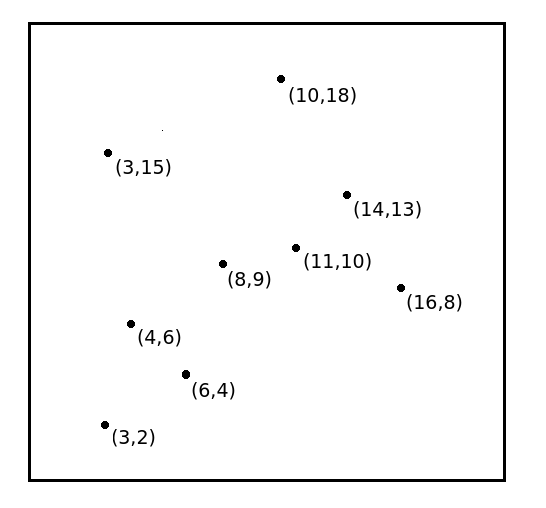
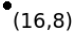
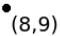
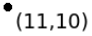
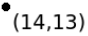

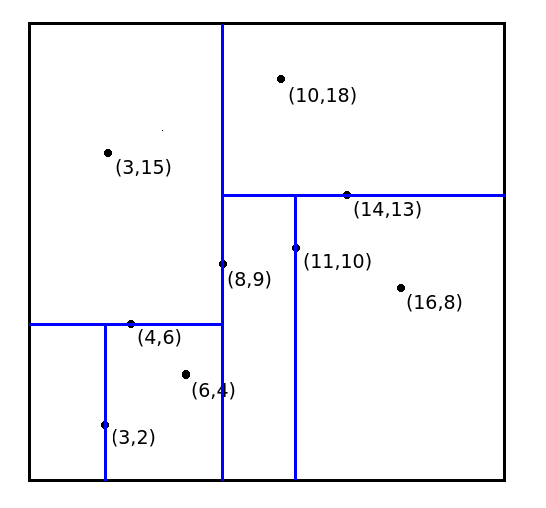










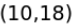

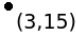
Figure 1: Points of 2D space and constructed Kd-tree for the points.
3. When the search algorithm reaches a leaf node, we stop the recursion and save that node as the current closest point to the query.
2
To search for k-nearest neighbours, we keep k closest points (instead of one), and only eliminate a sub-tree branch if the points in that branch cannot be closer than any of the current k closest points.
Addition
The assignment is broken up into a number of tasks, to help you progressively complete the assignment.
Task A: Implement the Nearest Neighbour Data Structures and their Operations (12 marks)
3
Implementation Details
Operations to perform on the implementations of the nearest neighbour search are specified on the command file. They are in the following format:
<operation> [arguments]
• C <id> <category> <x-coordinates> <y-coordinates> – check if a point (x,y) is in the point set of specified category. Id, category and coordinates must match for check to be success.
The format of the output of a search operation for (category, x, y) should return one neighbour per line. For each neighbour, it will be in the form:
|
|---|
4
| NearestNeighFileBased.java | Code that reads in operation commands from file then executes those |
|---|
on the specified nearest neighbour data structure. No need to modify this file.
|
|
| Skeleton code that implements a naive implementation of nearest neigh- |
bour searches. Complete the implementation (implement parts labelled“To be implemented”).
Table 1: Table of Java files.
where
• approach is one of “naive” or “kdtree”;
• data filename is the name of the file containing the intial set of points;• command filename is the name of the file with the commands/operations;• output filename is where to store the output of program.
Notes
• If you correctly implement the “To be implemented” parts, you in fact do not need to do anything else to get the correct output formatting. NearestNeighFileBased.java will handle this.
Test Data
We provide a sample set of restaurants, hospitals and education (schools) from Melbourne and sur-rounding area. It contains 1240 points. It is stored in file sampleData.txt. Each line represents a point. For each point/line, the format is as follows:
Write a report on your analysis and evaluation of the different implementations. Consider and recommend in which scenarios each approach would be most appropriate. The report should be no more than 5 pages, in font size 12 and A4 pages. See the assessment rubric (Appendix A) for the criteria we are seeking in the report.
Use Case Scenarios
The points generated to add, delete, or to find the nearest neighours to, will have an effect on the timing performance. If the distribution of these operations and search queries are available, we can use those to generate them. However, without the usage and search query data, it is difficult to specify what this distributions might be. Instead, in this assignment, for search queries and adding a point, uniformly sample the x and y coordinates from within the region boundaries. For points to remove, uniformly sample an existing point.
Analysis
As a guide, the report could contain the following sections:
• Explain your data generation and experimental setup. Things to include are (brief) explanations of the generated data you decide to evaluate on, the parameter settings you tested on, describe how the scenarios were generated (a paragraph and a figure or high level pseudo code), which approach(es) you decide to use for measuring the timing results..
• Your Java/Python source code of your implementations. Your source code should be placed into in the same code hierarchy as provided. The root directory/folder should be named as Assign1-<partner 1 student number>-<partner 2 student number>-JAVA or Assign1-<partner 1 student number>-<partner 2 student number>-PYTHON. Below, we will discuss the Java
7
– Assign1-s12345-s67890-JAVA/generation (generation files, see below).
When we unzip your submission, then everything should be in the folder Assign1-s12345-s67890-JAVA.
6 Assessment
The assignment will be marked out of 30. Late submissions will incur a deduction of 3 marks per day, and no submissions will be accepted 7 days beyond the due date (i.e., last acceptable time is on 23:59, 17th of September, 2021).
Report (18/30):
The marking sheet in Appendix A outlines the criteria that will be used
to guide the marking of your evaluation report. Use the criteria and the
suggested report structure (Section 4) to inform you of how to write the
report.
8
| get M for assignment 1, but student B will getM Y. | |
|---|---|
| 8 | |
University Policy on Academic Honesty and Plagiarism: You are reminded that all submitted assign-ment work in this subject is to be the work of you and your partner. It should not be shared with other groups. Multiple automated similarity checking software will be used to compare submissions. It is University policy that cheating by students in any form is not permitted, and that work submitted for assessment purposes must be the independent work of the students concerned. Pla-giarism of any form may result in zero marks being given for this assessment and result in disciplinary action.
For more details, please see the policy at http://www1.rmit.edu.au/students/academic-integrity.
5-6 marks
|
||||||||||
|
|
|||||||||